Knowledge Maintenance, Gamification and Crowdsourcing
My latest interests are on the intersection of knowledge maintenance, gamification and crowdsourcing. In particular, I am interested in applying gamification and crowdsourcing techniques to knowledge base maintenance. Large knowledge bases contain a lot of generic as well as domain-specific information (roughly TBox) and often also large collections of facts (roughly ABox). While the first part tends to be rather theoretical and compact, the second tends to be quite simple and rather voluminous. Maintaining the first part is often a task of group of experts, while the second part might be maintained by lots of individual contributors (the crowd), with individual tasks being distributed inside games, specially designed or adapted for this purpose.
There are some rather interesting problems in this domain, and some of them are of both academic and commercial interest, such as expertise formalization and following matching of the expertise of a person with available tasks or vice versa.
Some of our experiments were online at Entitypedia Games.
Semantic Matching
My areas of interest included semantic matching, natural language metadata and natural language processing, although there are other related bits like minimal mappings and word sense summarization. My thesis started as an attempt to improve semantic matching and S-Match as a particular implementation of a semantic matching algorithm. Quite soon we realized that there are two major directions for improving precision and recall of semantic matching systems. First is improving natural language processing of metadata and in particular, language to logic translation quality. Second is expanding background knowledge, generic as well as specialized, domain-specific knowledge.
Semantic matching can be seen as a generic operator, able to discover semantic relations. In this quality, it has many applications. In addition to obvious ones, such as matching two catalogues or schemas, semantic matching algorithms can enable semantic search. Semantic matching can also enable classification of documents into a catalogue.
Understanding and Processing Natural Language Metadata
My PhD thesis deals mostly with understanding natural language metadata. What exactly do we mean by that? Semantic matching algorithms often need to match structures which are expressed in natural language, such as hierarchies, thesauri, lightweight ontologies, database schemas and business catalogues. Although it remains natural, the kind of language used in these structures is characterized by brevity, lack of context and inclination towards using limited syntax with mainly nouns and adjectives organized into noun phrases. Often words are not separated by spaces, but rather by dashes or case. Abbreviations are also frequently used.
These differences separate such pieces of natural language into a new domain, or subset of language, which we call natural language metadata. These differences also make standard NLP tools less precise when processing such language and pose some challenges for correct processing.
Some commonly encountered examples of natural language metadata include labels used in personal or email folder hierarchies and web directories, such as «Knowledge» and «AccessControl».
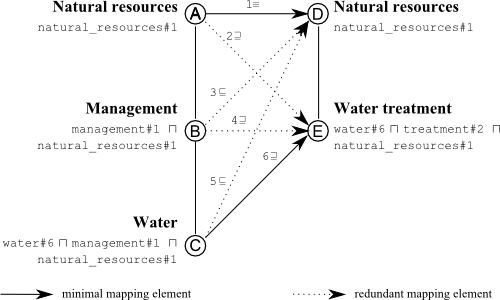
Given the hierarchy like in the example, the goal is to translate it into a formal language, preserving as much sense as possible and being accurate in the same time. As a formal language we use propositional description logics. As a source of concepts, any dictionary can be used. In particular, we use WordNet. Thus, «Water treatment» becomes «water#6 & treatment#2», where words with dashes and numbers are WordNet senses used as concept identifiers. After translation is done, semantic matching algorithm can match the formulas by expressing the matching task as a logic problem and solving it using a knowledge base and a satisfiability reasoner.